PROJECT: Internship Diary
This portfolio provides an overview of my contributions to the software engineering project Internship Diary.
Overview
Internship Diary is a desktop-based internship application tracking software.
The idea for this software came about when we realised that the nature of a computer science degree is internship-driven; in the sense that having the best possible internship experience during candidature will greatly improve your chance of landing a good first job. Having said that, internship application is often a tedious process as companies having different hiring processes and requirements.
We set out to tackle this pain point — by coming up with a solution to help computer science students manage and streamline their internship application journey. We aim to make every student’s internship hunt during their four years as a computer science undergraduate a pleasant one, and hopefully maximise their chances of landing the best possible internship.
Internship Diary offers a one-stop solution for users to organise and track their internship applications. It enables users to retrieve any information about their internship applications easily so that they can keep themselves updated with the companies they have applied to. This will motivate students to freely apply for many different companies and roles because they know that Internship Diary is always keeping their applications organized. Consequently, this may improve their chance of landing an internship.
Summary of Contributions
Enhancements
-
Implemented the Archival System
-
What it does: Allows users to move their internship applications between the main list and the archival list.
-
Justification: This feature is important as it helps users to keep their internship applications organized. Whenever there are internship application(s) that are no longer relevant, the user can archive those internship applications so that it "de-clutters" their main list. This allows them to focus on the internship application(s) that are more important.
-
Highlights: The archival feature seems trivial as it is usually a staple feature in many tracking applications. However, it was challenging to decide on a design implementation for our use case such that the feature is sustainable and extensible. Due to the chosen design, there was a need to implement a form of observer pattern to handle reactivity issues — this became another important design consideration.
-
-
Implemented the Observer Pattern Design
-
What it does: Provides a robust solution to keep UI in sync with the state of backend data.
-
Justification: As we started to introduce many UI elements that require various data and reference from the backend, it became difficult to manage the delivery of such data to the UI. To prevent coupling between the elements with our backend, and to ensure the UI can be updated with the latest data changes, we needed to implement the observer pattern.
-
Highlights: Researching about and implementing the observer pattern design. I had to find out exactly how the mechanism works and the options out there for us to integrate it into our project. There was quite a bit of trial-and-error in testing out the options so that we can find the best implementation / library for our situation.
-
-
Implemented Multi-Execution Type functionality for Removal-Based Commands
-
What it does: Allows users to execute removal-based commands like
archive,unarchive,deleteon multiple internship applications (by index, indices, or field). -
Justification: This would greatly aid users in organising their internship applications. Having to archive your internship applications one-by-one would not be a pleasant experience for the user.
-
Highlights: To design and implement this feature well is not easy. There were extensive discussions with the team regarding the most suitable implementation (not the best) to go ahead with. We had to consider aspects like timeline, amount of refactoring, conflicts with existing implementations, and other issues.
-
-
Implemented the Statistics feature
-
What it does: The statistics feature dynamically generates relevant metrics from the list of internship application(s) in the current view.
-
Justification: The hunt for internship can be seen as a journey of growth in terms of personal and professional development. The statistics feature provides users with important information about their internship application journey in terms of numbers, which the user can interpret and generate insights.
-
Highlights: Implementing the Statistics feature on its own was straightforward. The difficulty lies in how it can be implemented in an extensible manner. For example, the addition of a new status would not require the refactoring of model. This required careful design considerations.
-
Code Contribution
All of my contributions can be found here: RepoSense Report
Other Contributions
-
Project Management:
-
Actively managed team repository’s issue panel by adding, assigning, labeling, and closing issues.
-
Ensured that the team is heading in the right direction by monitoring the development progress and bringing up important issues.
-
-
Documentation
-
Contributed extensively to both the User Guide (UG) and Developer Guide (DG).
-
-
Major Refactoring of the Original Codebase
-
Allowed the team to proceed morphing the product and implementing features (PR #54)
-
-
Bug Fixes
-
Community:
Contributions to the User Guide
Given below are sections I contributed to the User Guide. They showcase my ability to write documentation targeting end-users. |
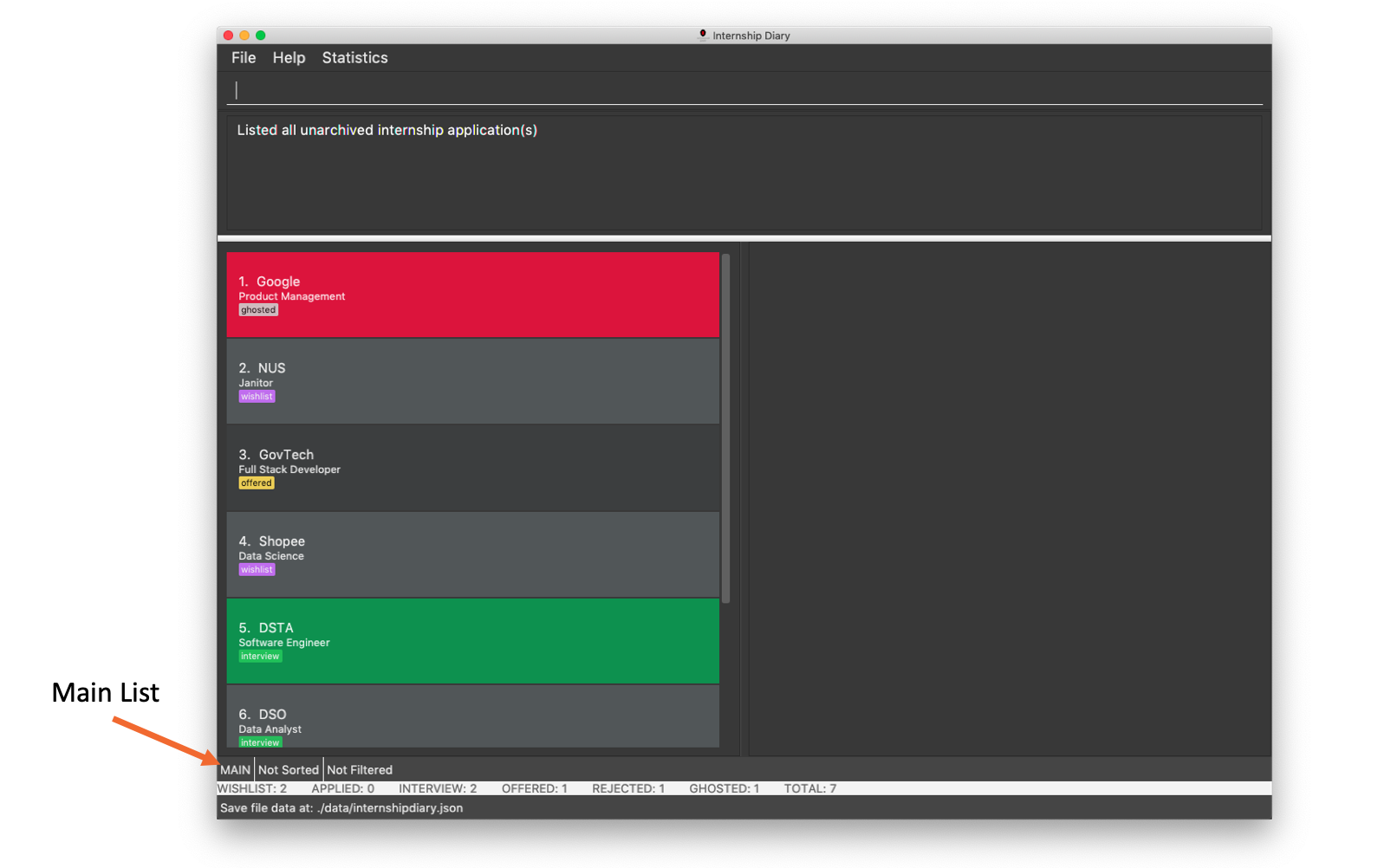
Viewing unarchived internship applications: list
Displays unarchived internship applications. This is known as your main list.
Format: list
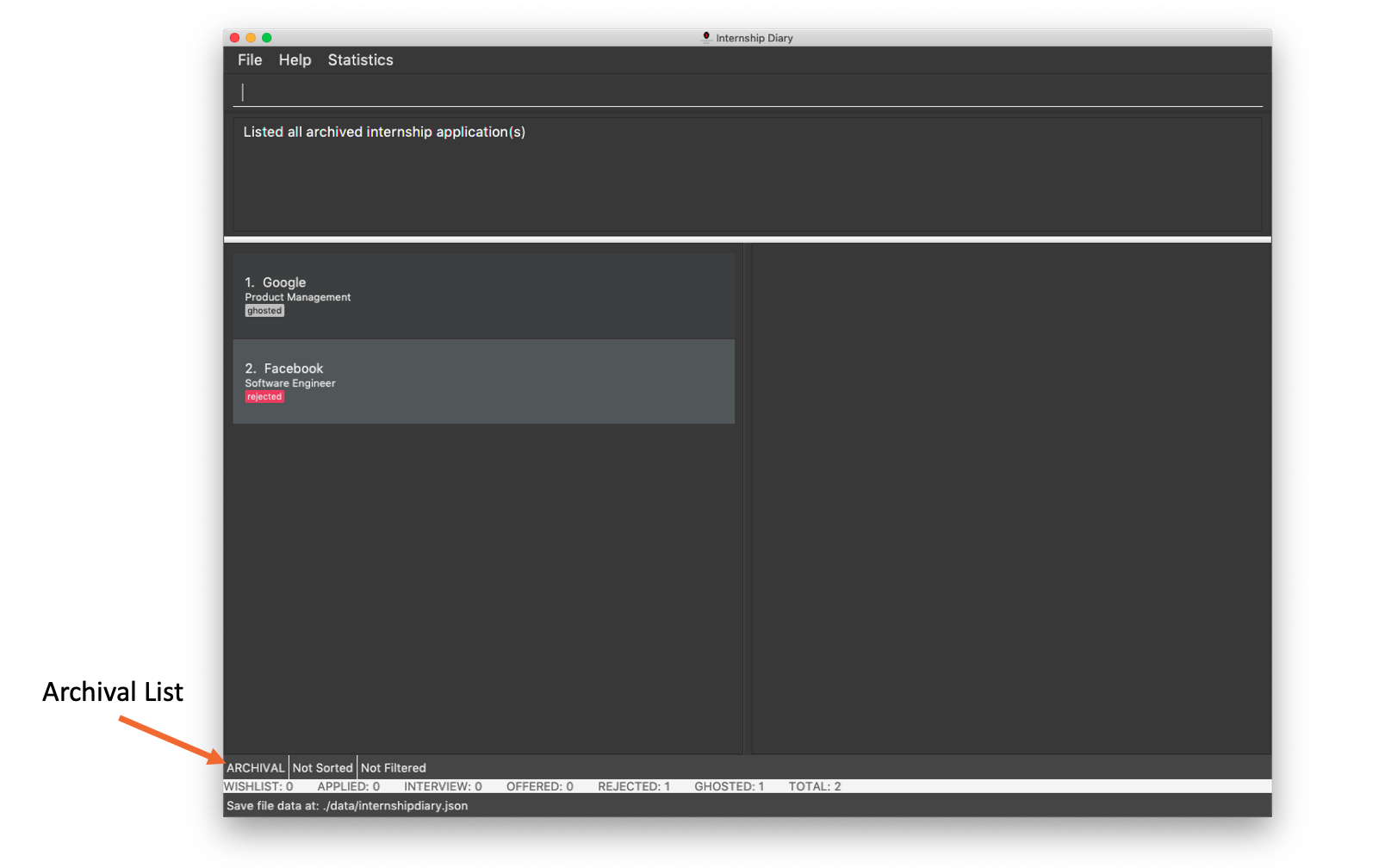
Viewing archived internship applications: archival
Displays archived internship applications. This is known as your archival list.
Format: archival
Deleting internship application: delete
Deletes internship application from the current list.
Formats:
-
delete INDEX -
delete INDEX, [INDEX],… -
delete s/STATUS [STATUS]…
Example(s):
-
list
delete 2
Deletes the 2nd internship application from the main list. -
list
delete 1, 2, 3
Deletes the 1st, 2nd, and 3rd internship applications from the main list. -
archival
delete s/applied
Deletes all the internship application(s) with theappliedstatus from the archival list. -
archival
delete s/applied rejected
Deletes all the internship application(s) with theappliedorrejectedstatus from the archival list.
Archiving internship application: archive
Moves internship application from the main list to the archival list.
Formats:
-
archive INDEX -
archive INDEX, [INDEX],… -
archive s/STATUS [STATUS]…
Example(s):
-
list
archive 2
Archives the 2nd internship application in the main list. -
list
archive 1, 2, 3
Archives the 1st, 2nd, and 3rd internship application in the main list. -
list
archive s/applied
Archives all the internship application(s) with theappliedstatus in the main list. -
list
archive s/applied rejected
Archives all the internship application(s) with theappliedorrejectedstatus in the main list.
Unarchiving internship application: unarchive
Moves internship application from the archival list to the main list.
Formats:
-
unarchive INDEX -
unarchive INDEX, [INDEX],… -
unarchive s/STATUS [STATUS]…
Example(s):
-
archival
unarchive 2
Unarchives the 2nd internship application in the archival list. -
archival
unarchive 1, 2, 3
Unarchives the 1st, 2nd, and 3rd internship application in the archival list. -
archival
unarchive s/applied
Unarchives all the internship application(s) with theappliedstatus in the archival list. -
archival
unarchive s/applied rejected
Unarchives all the internship application(s) with theappliedorrejectedstatus in the archival list.
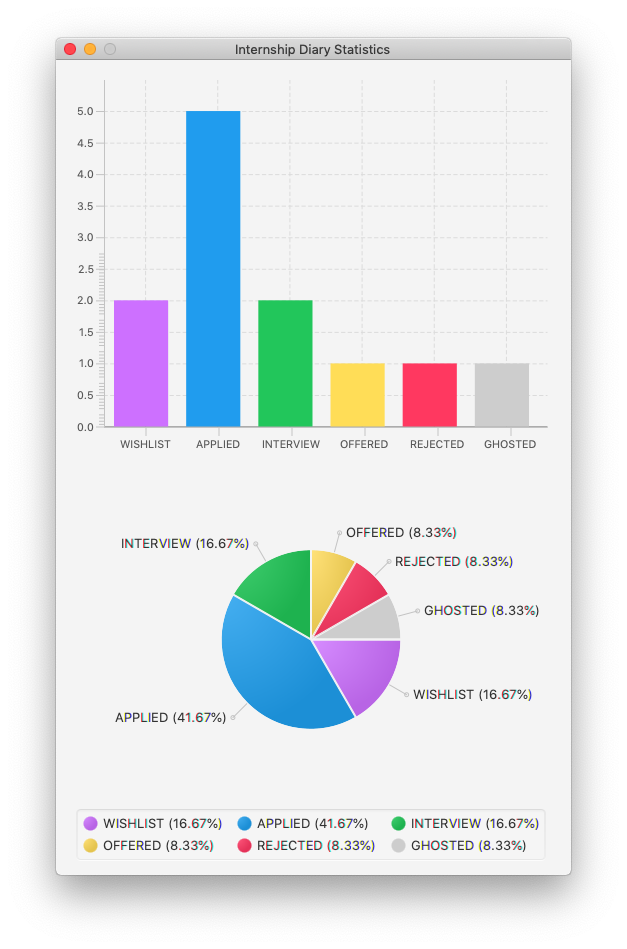
Retrieving statistics: stats
Displays the statistics about your internship application(s) on the current list.
It will open a separate window that contains a bar chart and a pie chart.
The statistics will dynamically update as you update the current list (e.g. switching between main and archival list).
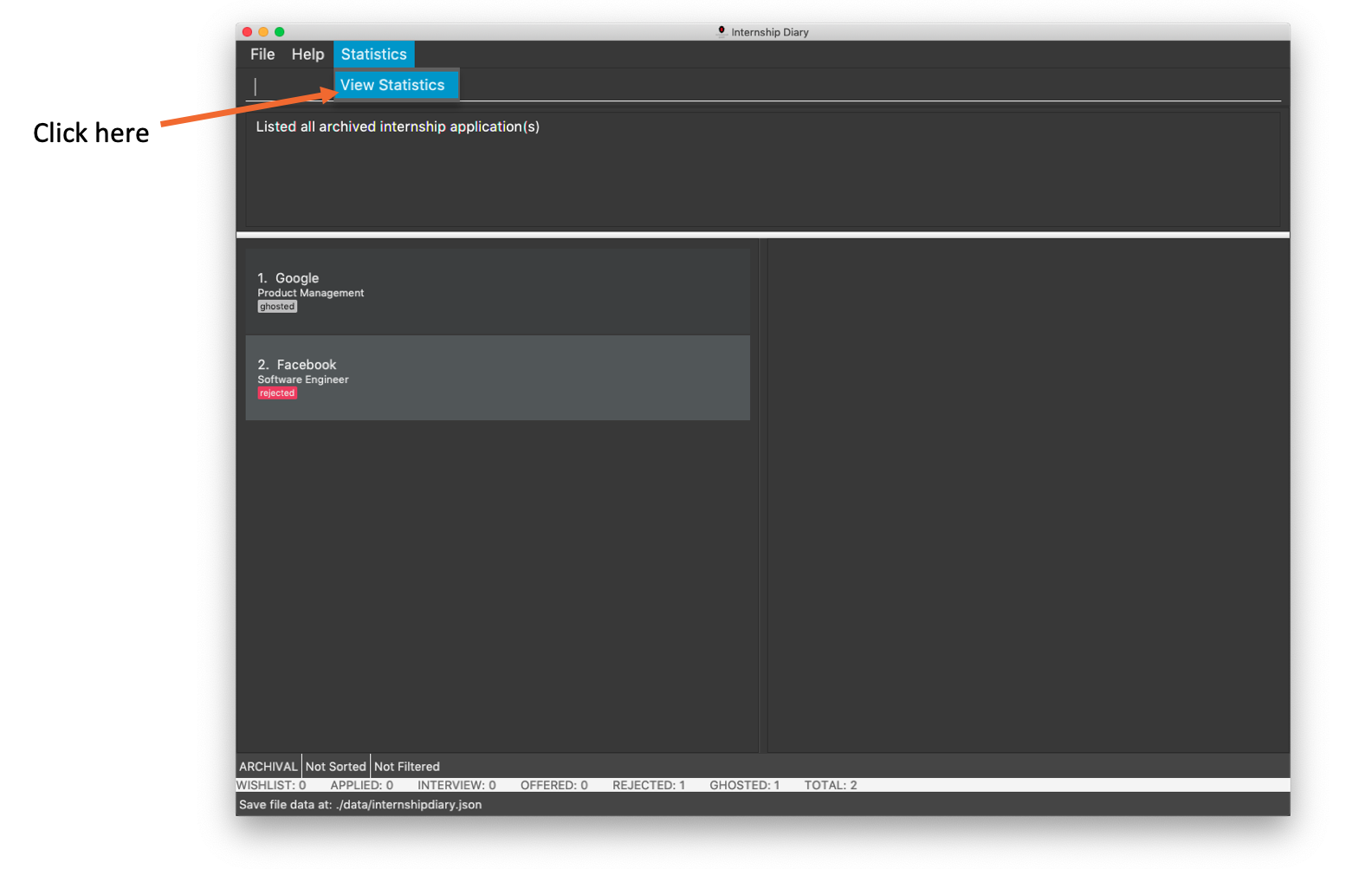
Format: stats
stats is executed| Alternatively, you may use your mouse to click on "Statistics" and then "View Statistics" to bring up the statistics window. |
Contributions to the Developer Guide
Given below are sections I contributed to the Developer Guide. They showcase my ability to write technical documentation and the technical depth of my contributions to the project. |
Archival System
This feature allows users to store chosen internship application(s) into the archival.
The entire system is driven by two mechanisms:
-
the ability to switch views between the archived and unarchived list of internship application(s)
-
the ability to move internship application(s) into the archived list and vice-versa
The two mechanisms can be further broken down into the following four commands: list, archival, archive, and unarchive.
List & Archival
To handle the ability for a user to switch views, we implemented the commands list and archival:
-
listallows the user to view the unarchived internship application(s) -
archivalallows the user to view the archived internship application(s)
From here on, we will refer to the list of unarchived internship application(s) as the main list, and the list of archived internship application(s) as the archival list.
Beyond the primary purpose of allowing users to switch between their view of main and archived list of internship application(s),
list and archival also helps to verify that the archive and unarchive commands are used appropriately.
This means that a user should not archive an internship application when it is already in the archival — doing so will raise an exception.
This is identical for the unarchive command in the main list as well.
Implementation
The class diagram below depicts the important methods and attributes that provide us the ability to switch views between the main list and the archival list.
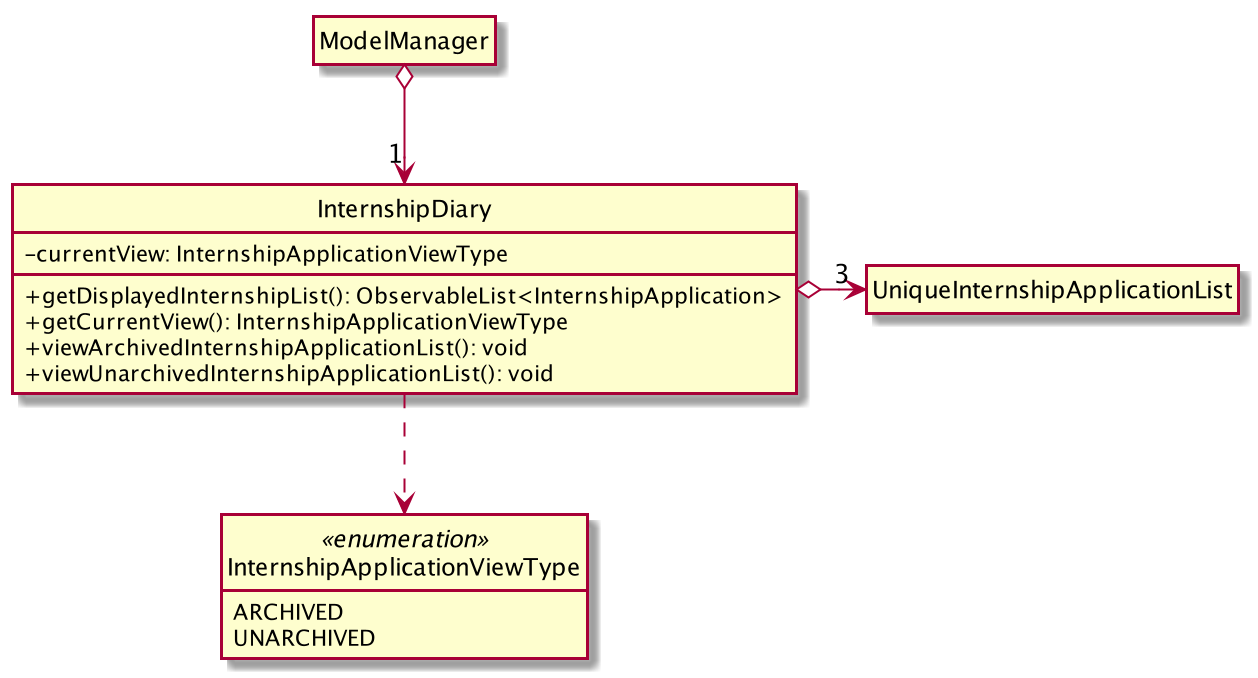
InternshipDiary that showcases the methods and attributes required for view-switchingThe object diagram below illustrates the three UniqueInternshipApplicationList objects maintained by InternshipDiary:
-
displayedInternships -
archivedInternships -
unarchivedInternships
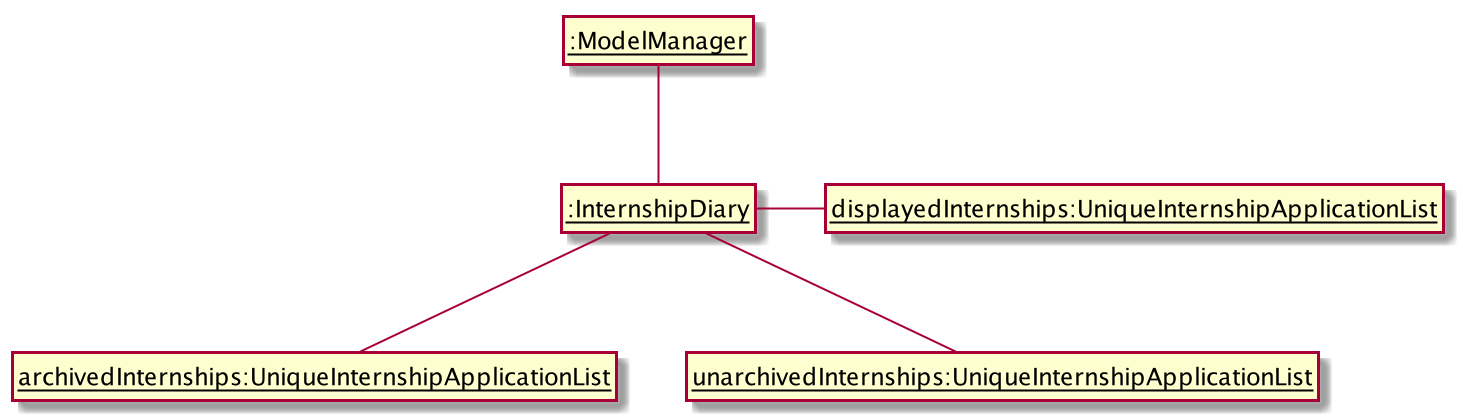
UniqueInternshipApplicationList objects maintained by InternshipDiaryAs the name suggests, displayedInternships is the list that is shown to the user in the GUI. It references either
archivedInternships or unarchivedInternships at any one time.
When a user is viewing the main list, displayedInternships references unarchivedInternships.
And when a user is viewing the archival list, displayedInternships references archivedInternships.
The following sequence diagram illustrates how an archival command is executed.
The list command is similar to archival.
You may use the same sequence diagram for the list command.
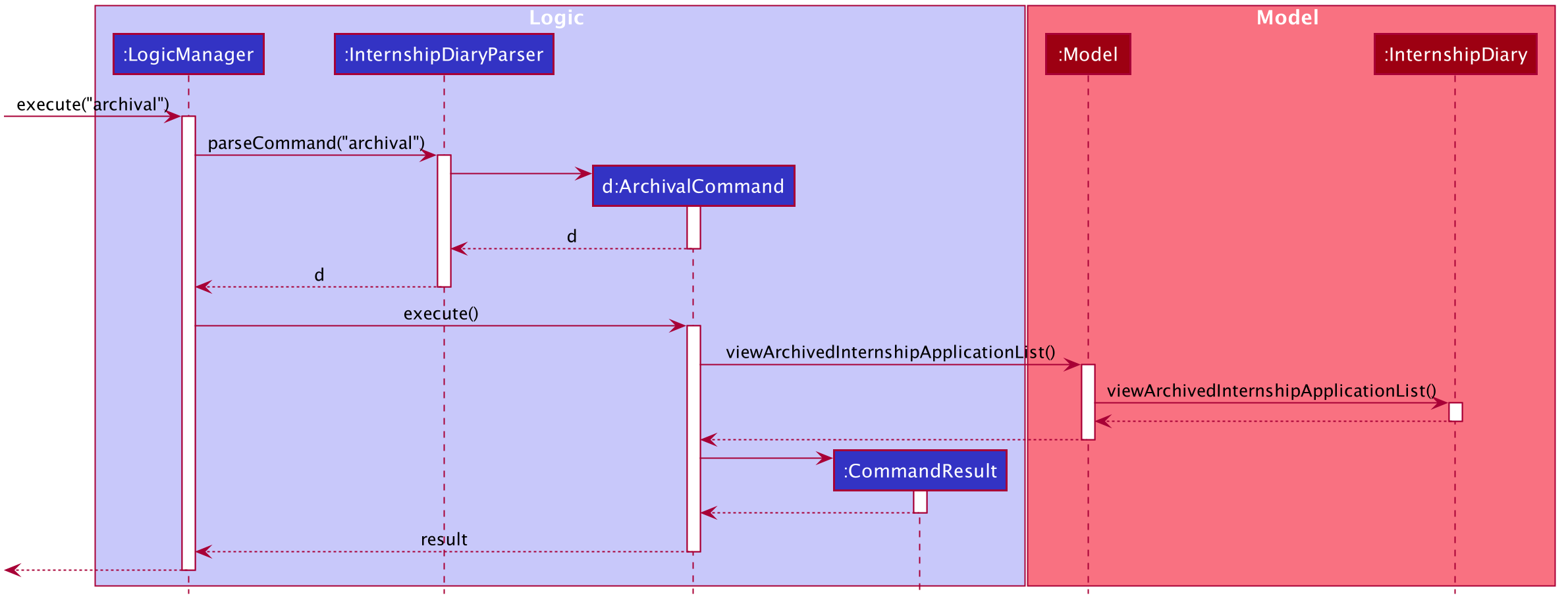
archival CommandThe following code snippet is retrieved from the InternshipDiary class.
It illustrates the internal workings of how we switch the view between the archived list and the main list.
public void viewArchivedInternshipApplicationList() {
this.displayedInternships = archivedInternships;
this.currentView = InternshipApplicationViewType.ARCHIVED;
firePropertyChange(DISPLAYED_INTERNSHIPS, getDisplayedInternshipList());
}
It can be seen explicitly from the code snippet that we make use of referencing to switch between the views of archival and main list.
However, such implementation brings about issues with reactivity — where elements that reference displayedInternships will not be aware of the reference change in displayedInternships whenever the user executes archival or list.
Therefore, in the above scenario, users would still see the main list after executing the archival command.
In order to resolve this issue, we need to employ the observer pattern design.
The broad idea is to assign each UI element to be an observer and InternshipDiary to be the observable.
Consequently, whenever there is a state change to InternshipDiary, the list of observers will be notified and updated automatically.
To achieve this observer pattern, we made use of the PropertyChangeSupport class and the PropertyChangeListener interface.
PropertyChangeSupport is a utility class to support the observer pattern by managing a list of listeners (observers) and firing PropertyChangeEvent to the listeners.
A class that contains an instance of PropertyChangeSupport is an observable.
On the other hand, a class that implements the PropertyChangeListener interface is an observer.
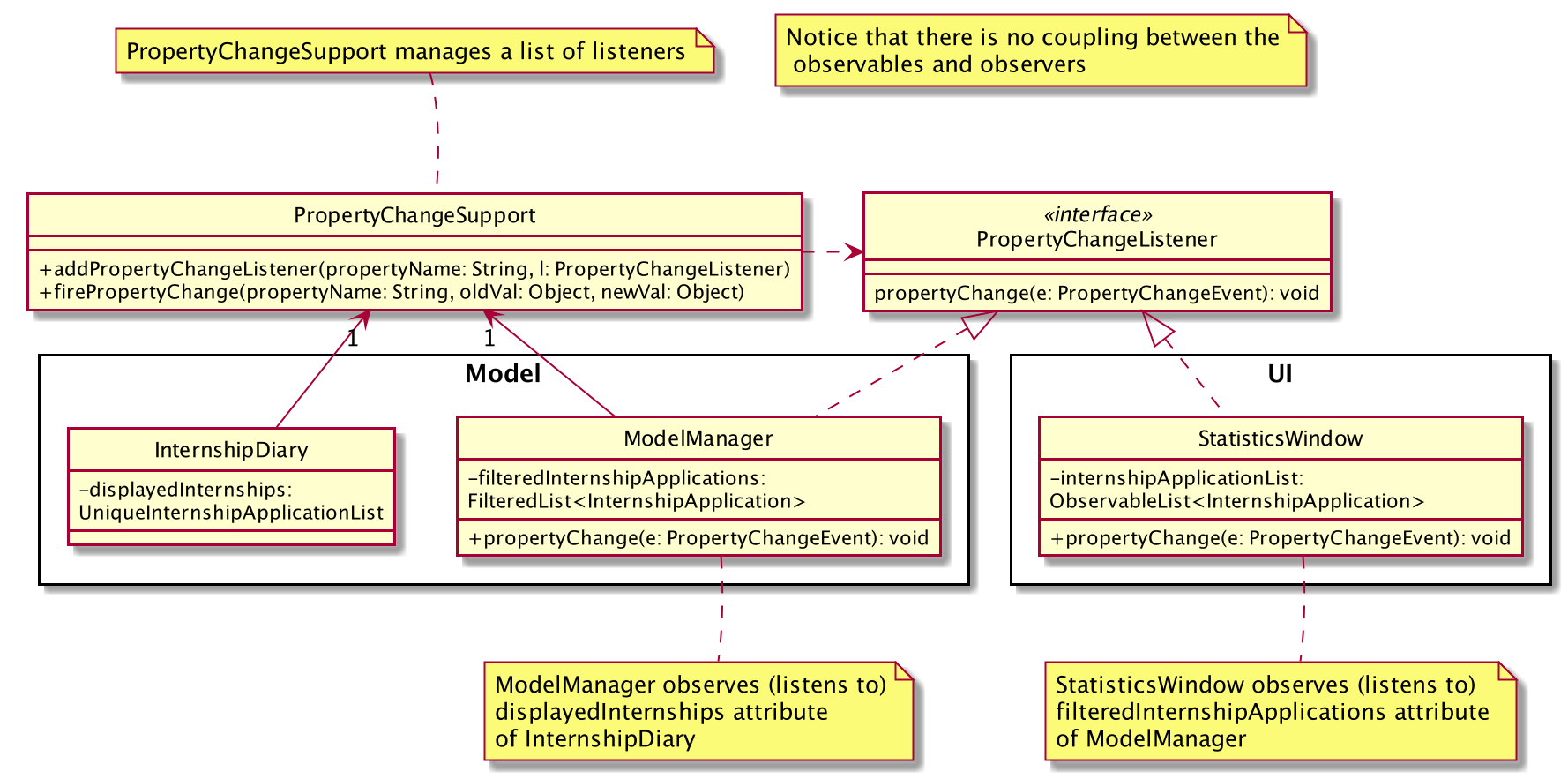
The class diagram above showcases our implementation of a two-tier observer-observable structure:
-
InternshipDiaryis an observable -
ModelManageris both an observable and observer-
It observes any changes to
displayedInternshipscontained inInternshipDiary
-
-
StatisticsWindowis an observer-
It observes any changes to
filteredInternshipApplicationscontained inModelManager
-
|
We will briefly discuss how the observer pattern works in our implementation.
Whenever an object wants to observe changes in another object, it will call the addPropertyChangeListener function of the PropertyChangeSupport instance from the appropriate object that it wishes to observe.
It will also have to specify which property of that object it wants to observe.
In our case, when ModelManager is created, it will call the addPropertyChangeListener function of the PropertyChangeSupport instance belonging to InternshipDiary.
The function call will look like this: addPropertyChangeListener("displayedInternships", this) where this
is a reference to ModelManager itself (so that it can be registered as a listener of the displayedInternships property of InternshipDiary).
The process is similar for any UI element that wants to observe the filteredInternshipApplications property of ModelManager.
As a result, whenever there is a change to the property displayedInternships in InternshipDiary, the PropertyChangeSupport instance of
InternshipDiary will call firePropertyChange to emit a PropertyChangeEvent to ModelManager.
The emitted event will trigger the propertyChange function of ModelManager.
ModelManager can then retrieve the new reference from the event and update its filteredInternshipApplications accordingly.
It will then repeat the event emission process to any UI element (e.g. StatisticsWindow) that is observing the
filteredInternshipApplications property.
The following activity diagram gives a high-level overview of the above event-driven process.
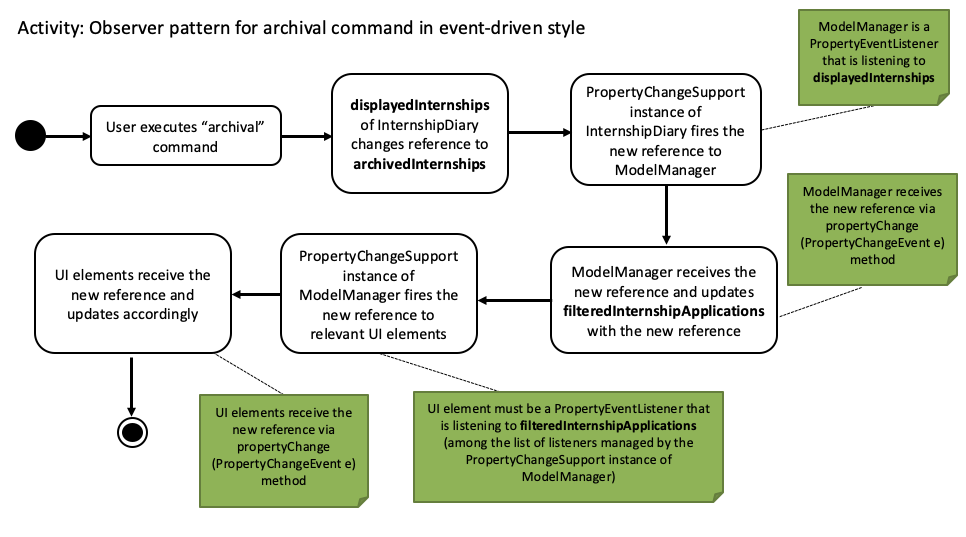
archival command
The two-tier observer-observable structure is necessary.
This is because list and archival only changes the reference of displayedInternships. |
When 'ModelManager' updates its property filteredInternshipApplications with the new reference, UI elements that reference filteredInternshipApplications
will not be aware of the reference update to filteredInternshipApplications.
Thus, ModelManager has to notify and update the UI elements as well.
As an extension, our team also implemented enumeration for each property that is being observed. This modification ensures type safety and a way for us to track what properties are observed. This is especially important when many properties are being observed.
Below is the updated class diagram with the implementation of ListenerPropertyType enumeration.
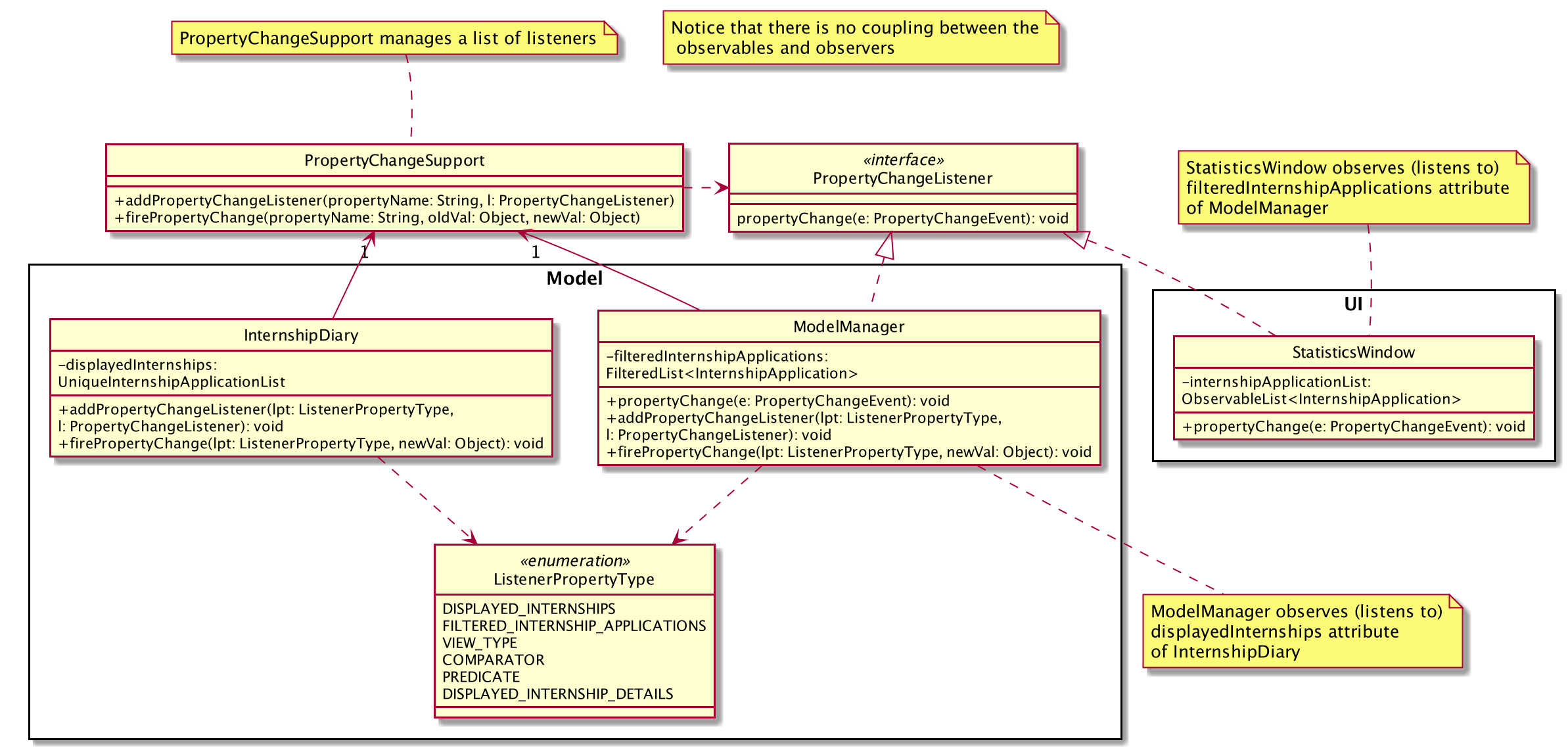
ListenerPropertyTypeAs seen from the diagram above, each observable will implement two additional methods to use ListenerPropertyType enumeration as parameters:
-
addPropertyChangeListener(ListenerPropertyType propertyType, PropertyChangeListener l) -
firePropertyChange(ListenerPropertyType propertyType, Object newValue)
This forms a layer of abstraction as we would not be allowed to call the addPropertyChangeListener and firePropertyChange methods of
PropertyChangeSupport directly.
Design Considerations
Aspect: How to implement the Archival View system on the backend
-
Alternative 1 (current choice): Maintain three
UniqueInternshipApplicationList:displayedInternships,unarchivedInternships, andarchivedInternships.displayedInternshipswill be used as the reference for other elements to retrieve the list of internship application(s) for usage. Whenever the user executesarchival, we will update the reference ofdisplayedInternshipstoarchivedInternshipsand vice-versa. In terms of storage, we will use only one list. This means that whenever we load the list of internship application(s) from the JSON save file, we will filter the internship application(s) appropriately intoarchivedInternshipsandunarchivedInternshipsinInternshipDiary. When saving, we will combine botharchivedInternshipsandunarchivedInternshipsinto a single list for storage.-
Pros: No need to modify the storage and its relevant test cases. This provides stability in the refactoring process.
-
Cons: Potentially expensive in terms of computation. Furthermore, we will have to implement observer pattern to handle the reference changes.
-
-
Alternative 2 (previous choice): Manipulate the current view of the internship application list by using Predicate and FilteredList, along with the boolean isArchived variable in
InternshipApplication. This will easily help us determine which internship application should be rendered.-
Pros: Very easy to implement and less expensive in terms of memory and computation. No need to implement observer pattern as there will be no reference updates.
-
Cons: Potentially unsustainable as conflicts are likely to arise with commands that make heavy use of predicates (e.g.
Findcommand).
-
Aspect: How to implement the Observer Pattern
-
Alternative 1 (current choice): Use
PropertyChangeSupportclass andPropertyChangeListenerinterface from thejava.beanspackage to support our implementation.-
Pros: Easy and intuitive to use. Good built-in support. Seems to be highly recommended by other users.
-
Cons: Seemingly negligible for our usage.
-
-
Alternative 2: Use Java’s
Observableclass andObserverinterface.-
Pros: Seemingly negligible for our usage.
-
Cons: The package is deprecated. Harder to understand and implement.
-
Archive & Unarchive
To allow users to move internship application(s) between the main and archival list of internship application(s), we implemented the commands archive and unarchive:
-
archiveallows a user to move internship application(s) from the main list to the archival list. -
unarchiveallows a user to move internship application(s) from the archival list to the main list.
The following activity diagram depicts the behaviour of an archive command.
You may use it as a reference for unarchive as well.
The activity diagrams for both are very similar.
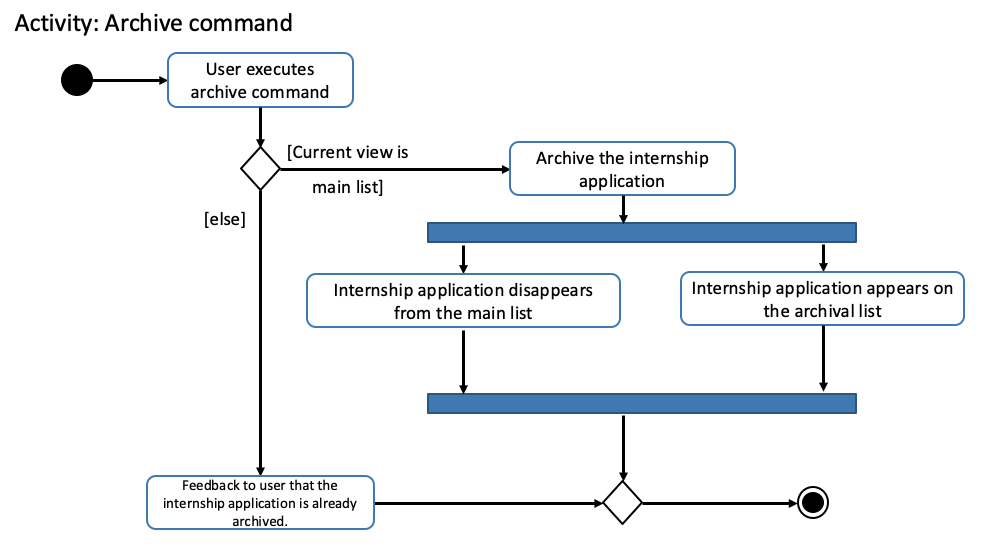
archive CommandWhile implementing the archive and unarchive commands, we realised that users may sometimes want to cherry-pick multiple internship application(s) to execute on or mass-execute on certain types of internship application(s).
For example, a user may want to archive all the internship application(s) that have the status of "rejected".
Commands like archive, unarchive, and delete can be seen as removal-based commands.
This is because the utility of such functions are very similar; in that they serve to modify the list by removing items.
Therefore, we specifically created a new class, RemovalBasedCommand, to extend the functionality of removal-based commands like archive, unarchive, and delete.
Through this new class, users will be able to execute the commands on multiple internship applications.
In the following section, we will delve slightly deeper and discuss about the lower-level implementation of the extended functionality.
Implementation
The following class diagram depicts our implementation of the extended functionality.
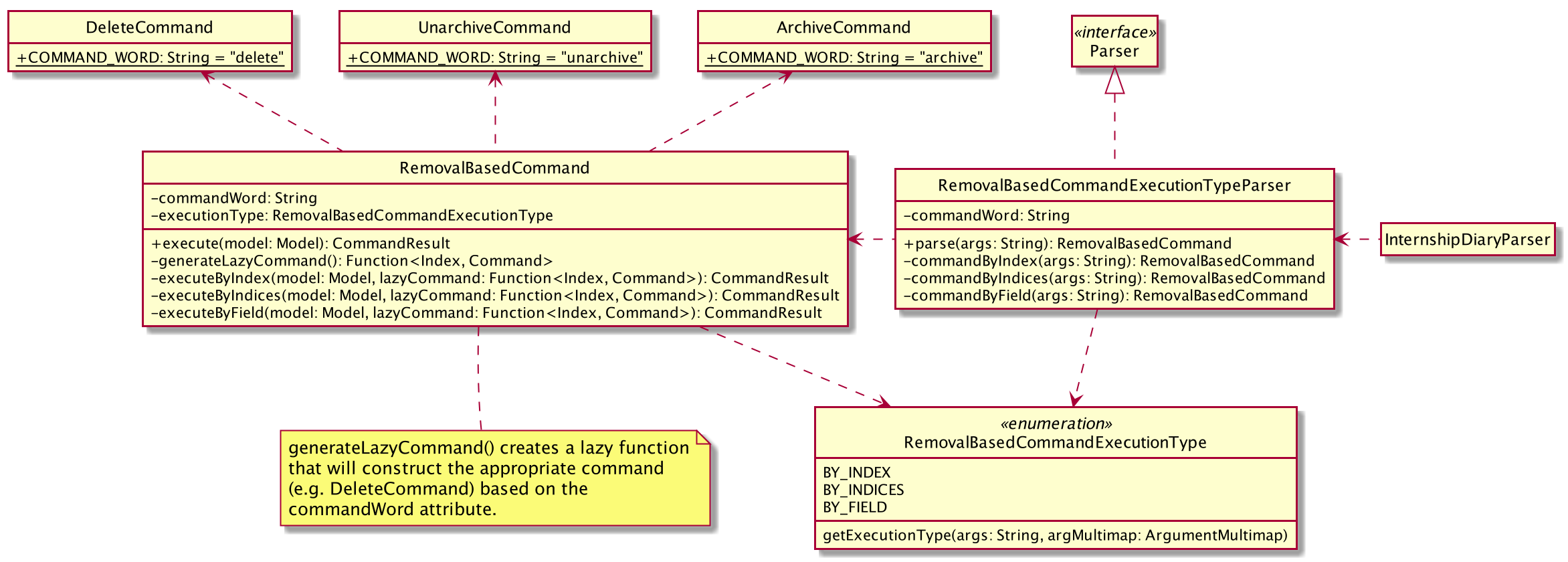
RemovalBasedCommand and RemovalBasedCommandExecutionTypeParser with its associated classesThe idea of the implementation can be summarized as follows:
-
The purpose of
RemovalBasedCommandExecutionTypeParseris solely to determine the execution type of the command by parsing the user input and callingRemovalBasedCommandExecutionType#getExecutionType. -
On the other hand,
RemovalBasedCommandis responsible for creating and executing the appropriate command based on thecommandWordthat was generated from the user input and passed down fromInternshipDiaryParser.
Users are able to execute removal-based commands like archive according to the execution types we have in the enumeration class RemovalBasedCommandExecutionType.
We have implemented the following execution types: BY_INDEX, BY_INDICES, and BY_FIELD.
For the execution type BY_FIELD, users can only execute by the Status field of an internship application currently.
The format of a removal-based command can take on any of the following forms:
-
commandINDEX -
commandINDEX, [INDEX], [INDEX], …
(where INDEX within the bracket is optional and there can only be as many INDEX as the number of internship application(s) displayed) -
commands/STATUS
(where STATUS refers to a valid internship application status)
Note that command can be any one of the removal-based commands.
It is important to note that each RemovalBasedCommandExecutionType works similarly.
At the core, all of them involves retrieving the index of an internship application to execute on.
The difference lies in the pre-processing stage — the steps an execution type takes to retrieve all the required indices.
Therefore, to ensure succinctness, we will only be illustrating the usage of the command archive with the execution type BY_FIELD.
Other variations of removal-based commands and execution types are similar.
The following sequence diagram provides a high-level overview of how the archive command with the execution type of BY_FIELD is executed in our application.
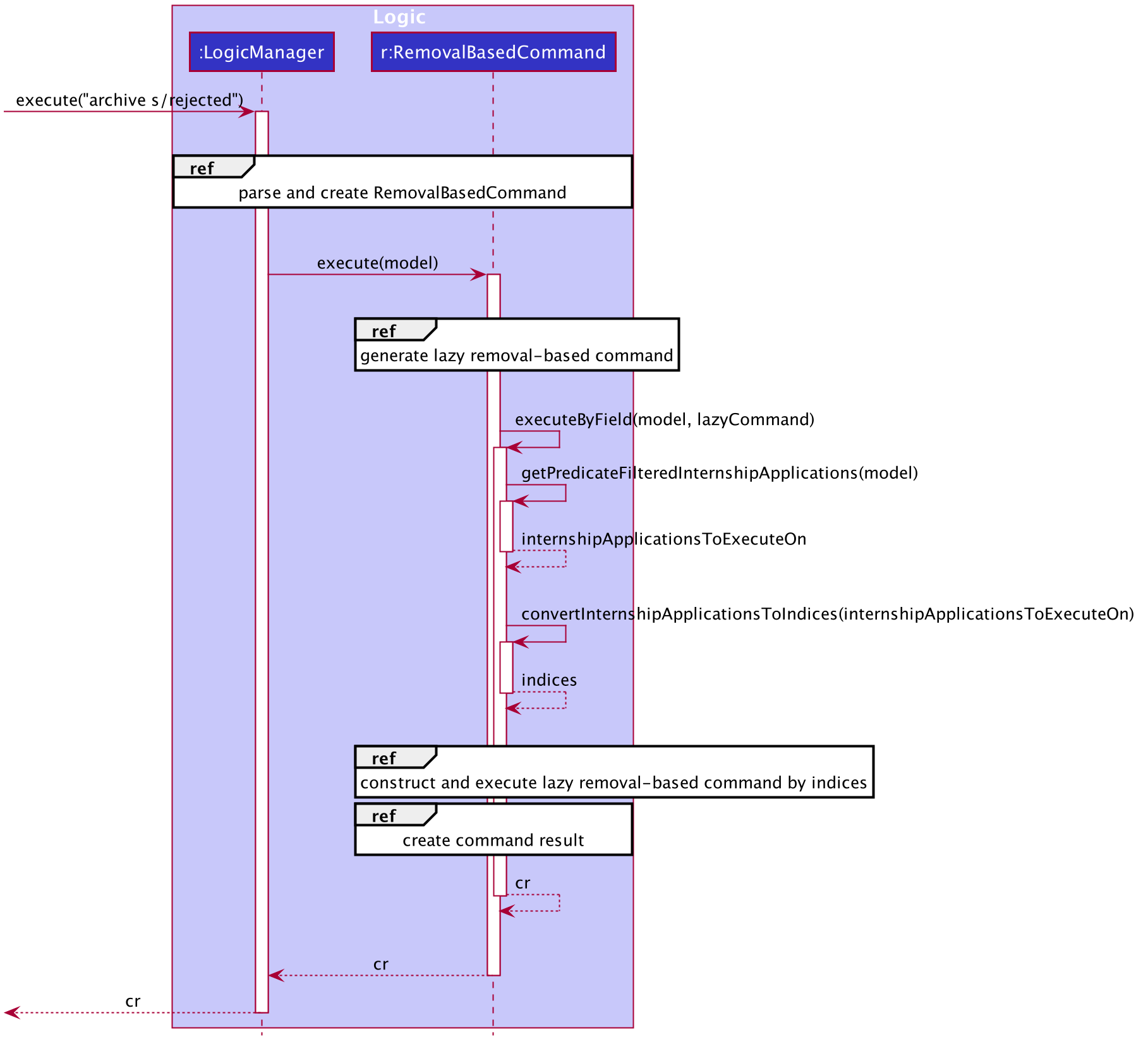
archive s/rejected commandAs illustrated in the diagram above, the pre-processing steps of BY_FIELD involves applying the appropriate predicate to filter the internship applications and then converting these internship applications to their respective index.
This provides us with required indices that we will execute the removal-based command archive on.
| We have implemented the mechanism to be reusable and extensible for new commands and execution types. |
This is evident in the sequence diagram above, where the different kinds of removal-based commands are abstracted from the diagram and referred to simply as RemovalBasedCommand.
This means that the above diagram is applicable to archive, unarchive, delete, and any other removal-based commands that we may wish to introduce in the future.
Furthermore, if we ever wish to create a new RemovalBasedCommandExecutionType (on top of BY_INDEX, BY_INDICES, and BY_FIELD), we may simply add a new alternative path to the diagram (or a new switch condition in terms of code).
The following sequence diagram captures how RemovalBasedCommandExecuteTypeParser parses the input and determines the execution type of the command.
It also shows how a RemovalBasedCommand is created with the appropriate RemovalBasedCommandExecutionType and command word.
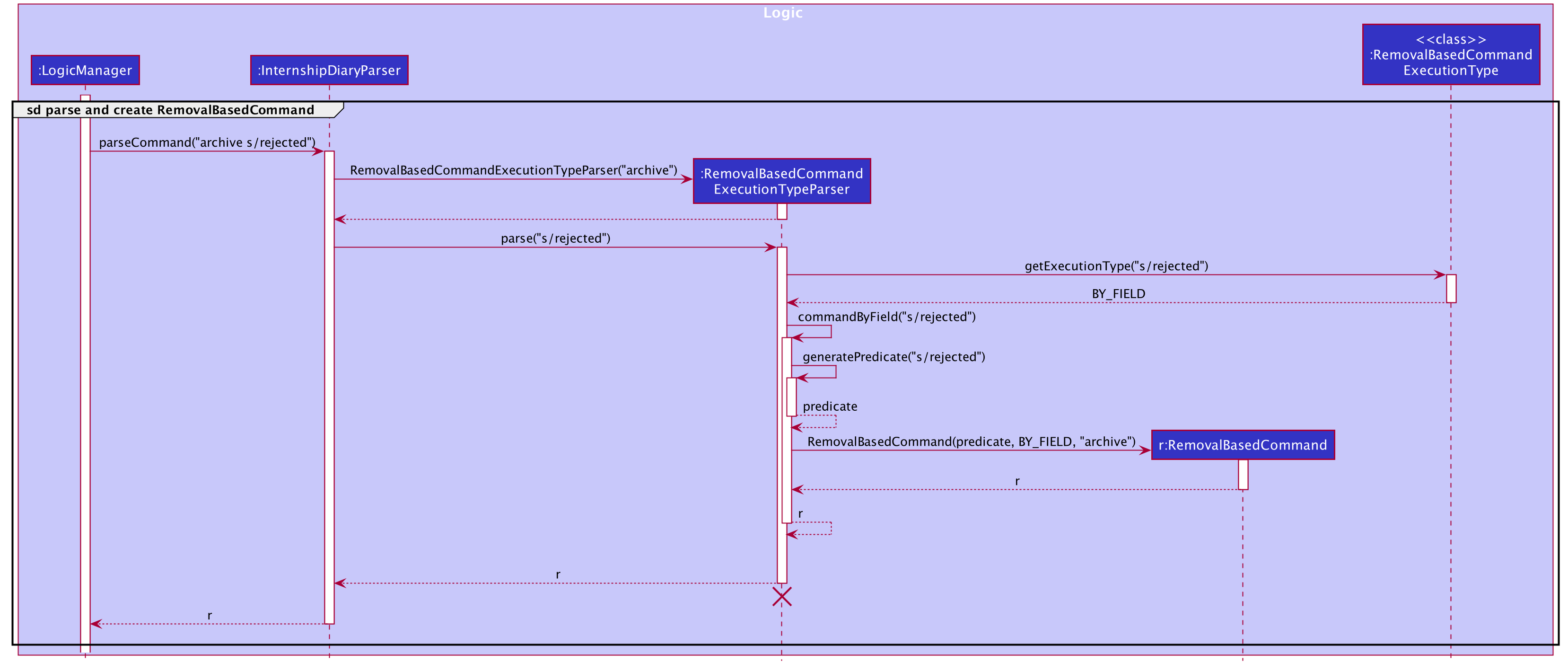
RemovalBasedCommandExecuteTypeParser parses input and determines the execution type of commandAs seen from the diagram above, the parser determined the execution type to be BY_FIELD and generated the appropriate predicate to construct a RemovalBasedCommand instance.
Based on the command word passed in to construct the RemovalBasedCommand instance, RemovalBasedCommand creates a lazy lambda function that can be called to construct the appropriate removal-based command for execution.
The following sequence diagram depicts the above behaviour.
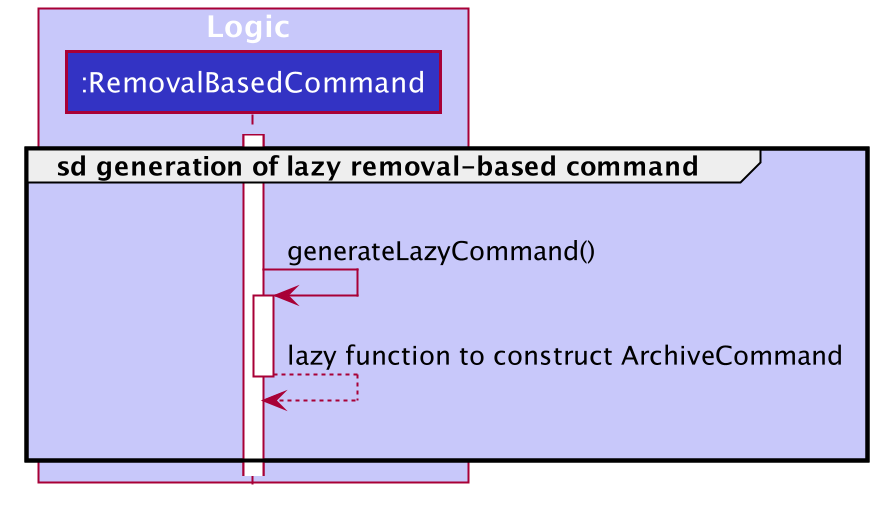
RemovalBasedCommand instanceAs the command word is archive, a lazy lambda function to construct an ArchiveCommand is returned.
The following sequence diagram captures the process of executing the lazy removal-based command on one index. This particular index allows us to retrieve the appropriate internship application.
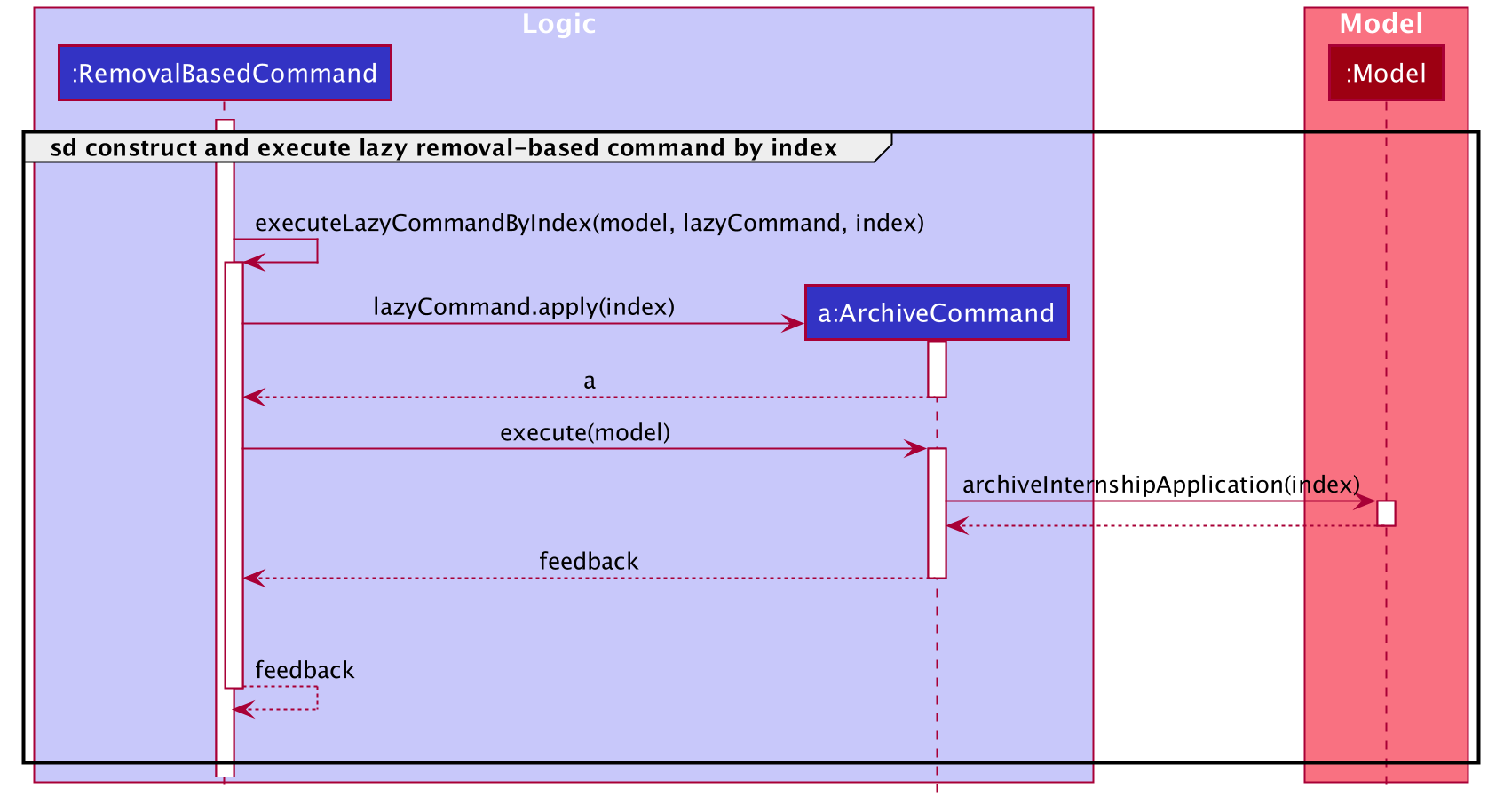
archive, on one indexIt can be seen that the previously-generated lazy command is executed in the above sequence diagram.
ArchiveCommand is constructed and subsequently executed on the index provided, by making the appropriate function call to the model to execute on the internship application.
In this case, archiveInternshipApplication is called.
The following sequence diagram captures the process of executing the lazy ArchiveCommand on indices.
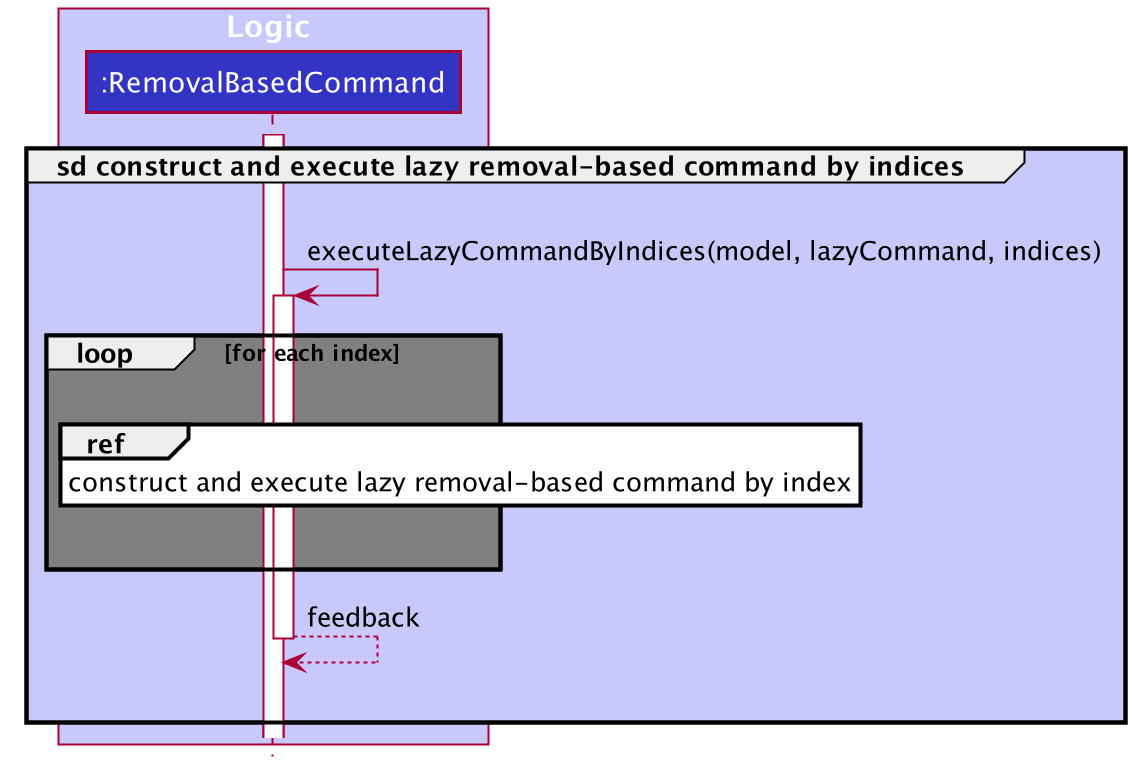
archive, on indicesAs seen above, executeLazyCommandOnIndices merely reuses the function executeLazyCommandOnIndex (from the previous sequence diagram) by running it on every index provided.
The feedback from each execution is cumulatively concatenated to form a single feedback.
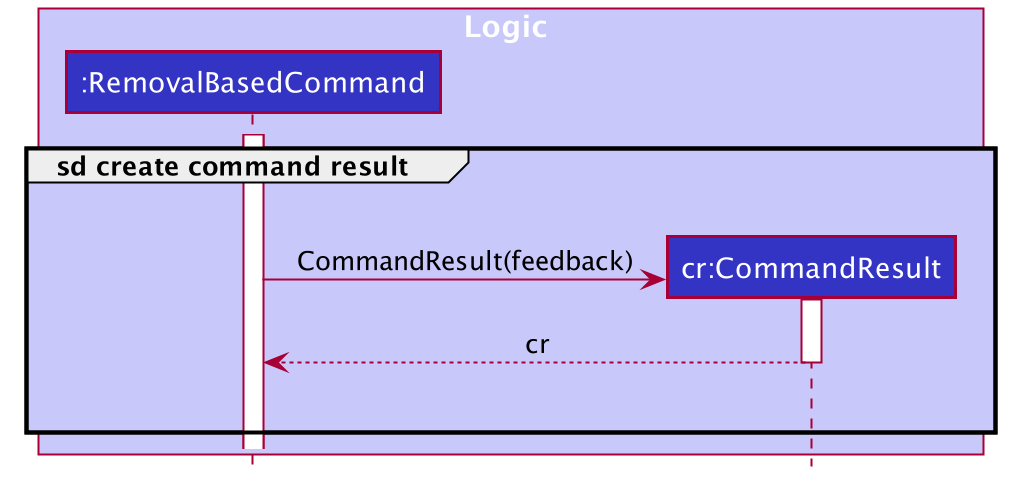
The following sequence diagram captures the process of re-creating the command result in RemovalBasedCommand by using the feedback obtained from the specific command execution, which is ArchiveCommand in our example.
RemovalBasedCommandDesign Considerations
Aspect: How to implement Multiple Execution Types for Removal-Based Commands
-
Alternative 1 (current choice): Use encapsulation to hold the appropriate command word, which will then be used to generate the removal-based command that will execute based on the execute type provided.
RemovalBasedCommandwill store the command word of the appropriate removal-based command and create the command whenRemovalBasedCommandis executed. This removal-based command will then be executed on the index/indices provided according to the execution type.-
Pros: Easier to implement and convey the idea to team members.
-
Cons: Will require multiple case handling (e.g. switch cases). Polymorphism may be a better solution in terms of code extensibility and elegance.
-
-
Alternative 2: Use polymorphism where each removal-based command extends the class
RemovalBasedCommandand inherit the appropriate execution type methods.-
Pros: Code will likely be more extensible and elegant.
-
Cons: Likely to require major redesigning and refactoring of existing logic codebase because we will have to modify
Commandclass. Furthermore, the changes may affect areas that we may not have considered. This is risky and will take a lot of time, effort, and team discussion.
-
Statistics Feature
This feature allows users to view relevant metrics about their internship application(s).
Currently, the tracked metrics include:
-
the amount of internship applications in each status
-
the percentage of internship applications in each status
Implementation
The following class diagram gives an overview of our implementation of the statistics feature.
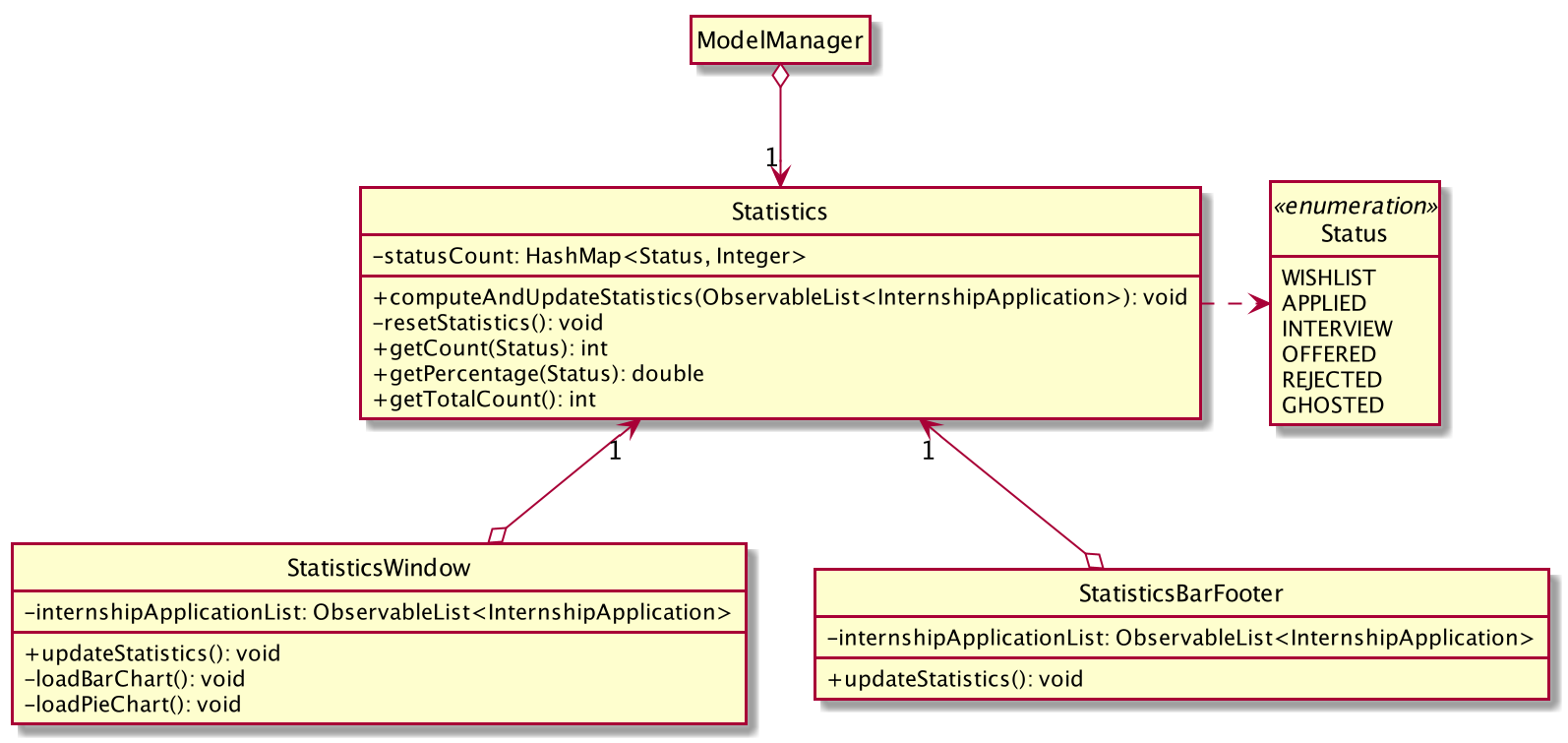
Statistics and its associated classesUsers will be able to view the metrics from two areas:
-
StatisticsBarFooter-
found at the bottom of the application in the form of a bar footer
-
serves as a quick view of the metrics in terms of counters
-
-
StatisticsWindow-
displayed on a separate window that is opened upon the command
stats -
serves as an additional graphical statistics interface for users to get a visual breakdown of the metrics
(currently in the form of a bar chart and a pie chart)
-
The Statistics object is used to generate statistics for any internship application list that it is given.
StatisticsWindow and StatisticsBarFooter each contains an instance of Statistics that helps them compute the relevant statistics whenever there is any update to the internship application list.
The internship application list can be updated either due to a change in reference in displayedInternships from InternshipDiary (e.g. archival and list) or any modifications to the current internship application list (e.g. add, delete, edit, archive, unarchive, find).
The following activity diagram illustrates how StatisticsWindow (StatisticsBarFooter shares the same workflow) is notified of the updates in the internship application list and how it subsequently updates the statistics.
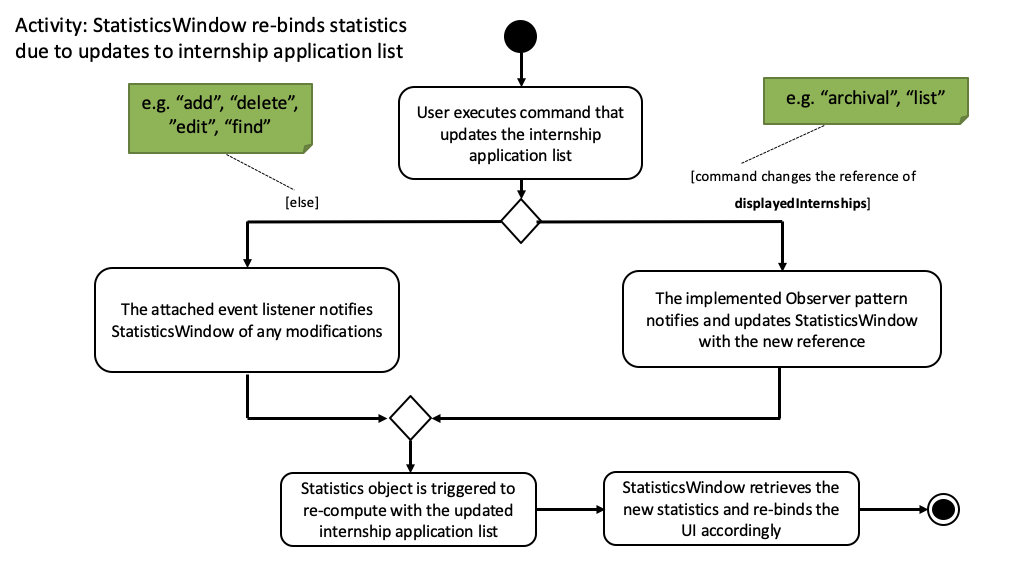
StatisticsWindow is notified of updates in the internship application list and how statistics is updated accordinglyUpon creation of the StatisticsWindow and StatisticsBarFooter, each of them will attach an event listener to the internship application list that it was given.
This event listener will notify them of any internal modifications to the internship application list.
On the other hand, both StatisticsWindow and StatisticsBarFooter will register themselves as observers as well.
This is so that the implemented observer pattern can notify them of any changes in the internship application list reference and update them with the new reference accordingly.
Any of the two updates above will trigger the Statistics to recompute with the updated internship application list.
StatisticsWindow and StatisticsBarFooter will then retrieve the required computed metrics from Statistics and re-bind the them to the UI accordingly.
Design Considerations
Aspect: Which list to retrieve data from to generate statistics
-
Alternative 1 (current choice): Use filtered ObservableList. The filtered list is dynamically updated by
findandsortcommand. The statistics model will generate statistics based on the dynamic filtering changes that occur in either the main list or archival list (the current view selected by user).-
Pros: Users will be able to choose which list they want to view the relevant statistics for. Works well with
archival,list, andfindcommands that dynamically changes the list. -
Cons: Often re-computation upon changes in the filtered list may cause some performance bottleneck.
-
-
Alternative 2: Use the base list that contains all of the internship application(s). The base list is not filtered according to predicate(s) set by users.
-
Pros: Require less re-computation compared to using filtered ObservableList, as it only re-computes upon addition(s), deletion(s), or changes in an internship application stored in the list.
-
Cons: May be unintuitive to some extent for users when the statistics do not tally with the current view of the list.
-
Aspect: How to store the statistics generated from data
A list of internship application(s) will be passed into the statistics model and upon function call, the statistics model will iterate through the list and generate/update the latest statistics accordingly.
-
Alternative 1 (current choice): Store the mapping between each status and count using a HashMap. The idea is to retrieve all the statuses available from the enum (whenever the statistics model is created) and create a HashMap with those status as the key and respective count as the value.
-
Pros: Extensible and reusable. Regardless of any changes, this system can dynamically handle the addition, deletion, or changes in statuses.
-
Cons: Seemingly negligible cons for our usage.
-
-
Alternative 2 (previous choice): Store each status count in separate variables that are initialized upon the creation of statistics model.
-
Pros: Straightforward and very easy to understand for future developers.
-
Cons: Very inextensible as we need to create new variables for new statuses each time.
-